Documenter la data, c'est vital. Se taper 400 procédures SQL à la main, c'est létal. Retour d'expérience sur une mission où nous avons combiné DataHub, Python et un LLM local pour transformer un enfer en victoire produit.

January 26, 2026
Documenter la data, c'est vital. Se taper 400 procédures SQL à la main, c'est létal. Retour d'expérience sur une mission où nous avons combiné DataHub, Python et un LLM local pour transformer un enfer en victoire produit.
Dans la vie d'un projet Data, il y a un moment fatidique : celui où l'on doit mettre de l'ordre dans le chaos. Récemment, nous avons accompagné une entreprise qui avait un très grand nombre de sources de données. Notre mission ? Nous avons un Data Catalog (nous avons choisi DataHub) pour récupérer toutes les structures de données éparpillées afin de les documenter, établir des connexions entre elle, afin de permettre aux équipes techniques et métiers de ne plus se perdre ou de choisir de mauvaises données.
Tout se passait bien, jusqu'à ce qu'on tombe sur "La Bête". Un outil d'analytics historique, vital pour les opérations, mais totalement opaque. Il reposait sur plus de 400 procédures stockées.
Pour les non-initiés, imaginez 400 recettes de cuisine écrites en hiéroglyphes (du SQL avec des jointures dans tous les sens), sans aucune explication sur les ingrédients (les colonnes) ou le résultat final. Personne ne savait vraiment d'où venait la donnée.
Le problème ? Pour rendre ces données exploitables dans le catalogue, il fallait tout documenter : expliquer chaque colonne, lister les tables sources, décrire la logique.
À la main, c'est plusieurs semaines de travail à temps plein. C'est le genre de tâche qui brise le moral d'une équipe quand il sont lancés dans une tâche répétitive et rébarbative. Alors on a décidé de laisser "l'huile de coude" au placard et de sortir l'artillerie lourde : l'automatisation par l'IA.
La situation de départ était claire, mais intimidante. Nous avions :
L'objectif était de créer, pour chaque procédure, une fiche "Glossaire" dans DataHub qui ressemble à ça :
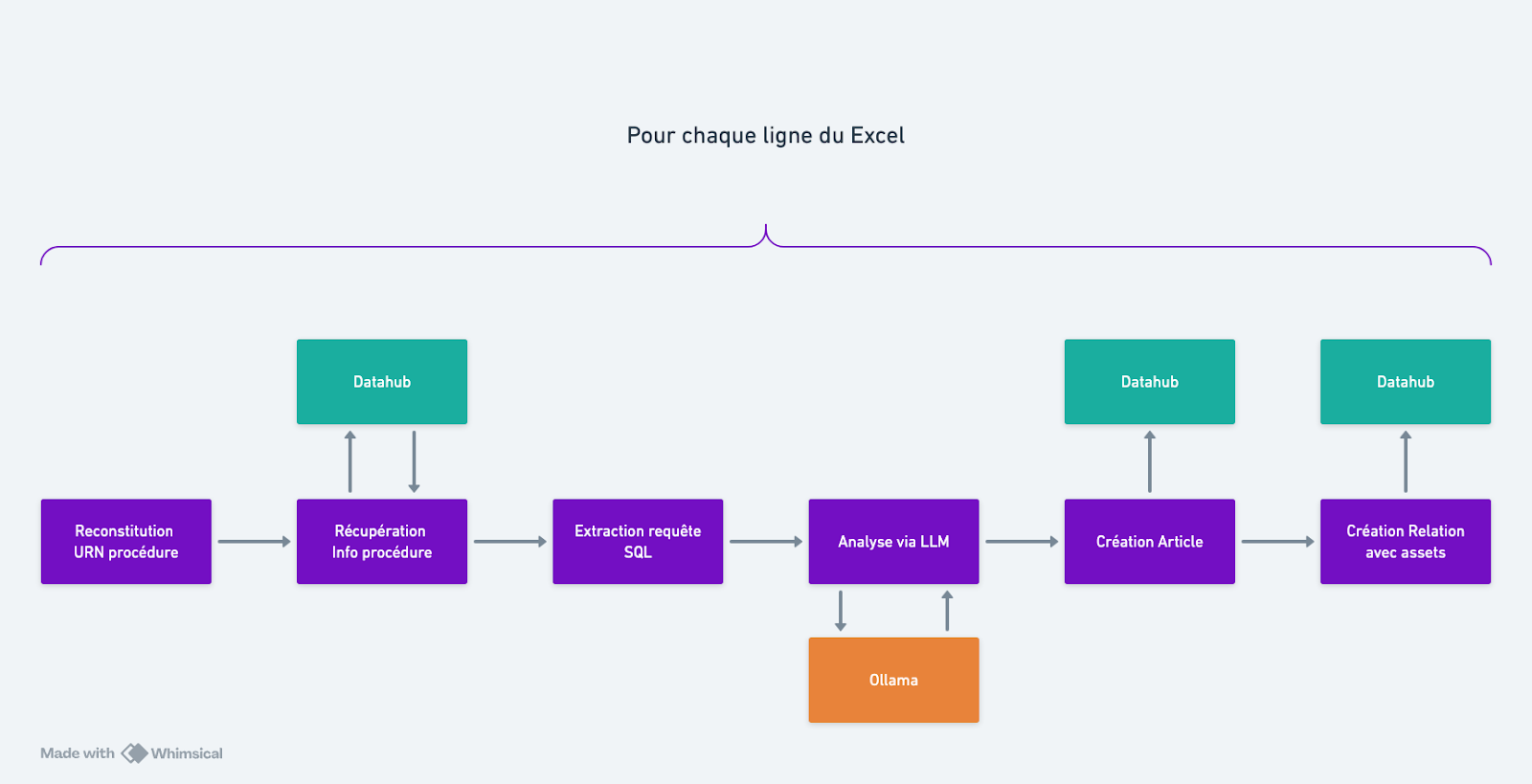
Pour y arriver sans y passer l'hiver, nous avons imaginé un pipeline simple : un script Python qui fait le chef d'orchestre entre l'API de DataHub et un modèle de langage (LLM).
Pour ce projet, pas question d'envoyer les schémas de base de données sensibles de notre client pour entraîner un modèle hébergé on ne sait où. Nous avons opté pour une approche Local LLM.
L'idée est simple : on récupère le code SQL via l'API DataHub, on le donne à manger à Qwen avec des instructions très précises, et on réinjecte le résultat propre dans le catalogue.
C'est ici que la magie opère (ou échoue). Au début, nous avons naïvement demandé à l'IA : "Analyse ce SQL et fais-moi un tableau".
Résultat ? Une catastrophe. Un coup le tableau était en HTML, un coup en Markdown, parfois il inventait des colonnes... Inexploitable par un script.
Il a fallu itérer pour trouver le System Prompt parfait. Voici les clés de notre succès :
Exemple concret :
Pour une procédure calculant une moyenne d'élève, l'IA nous génère désormais automatiquement ceci :
Nom de la colonne
Table d'origine
Champ d'origine
Description
Nom
Student
firstname, lastname
Concaténation
Moyenne
Grade
grade
AVG() par étudiant
Et juste en dessous, la liste propre des tables impliquées (Main.public.Student, Main.public.Grade) que notre script peut parser pour créer les liens automatiquement dans DataHub.
Une fois le script calé et le prompt validé, nous avons lancé la machine. Le script parcourt le fichier Excel, interroge DataHub, fait analyser le SQL par l'IA, et publie le résultat.
L'impact produit est immédiat :
Bien sûr, l'IA n'est pas parfaite à 100%. Mais elle fournit une "Base de départ" excellente (disons 90% du travail fait). La relecture humaine reste nécessaire, mais elle devient un contrôle qualité rapide plutôt qu'une rédaction laborieuse.
Si vous envisagez d'utiliser l'IA pour documenter votre dette technique, voici nos conseils :
Au final, un peu de code et d'IA nous ont permis de transformer une montagne infranchissable en une balade de santé. Et notre équipe ? Ils vont très bien, merci pour eux. Ils apprennent à prompter des LLM au lieu de faire du copier-coller.

Matters accompagne les startups et scale-ups à développer des solutions vertueuses pour l'environnement et la société. Nous organisons régulièrement des meetups et des conférences au cours desquelles les intervenants partagent leurs expériences sur des thématiques dédiées. Pour être informé.e de nos prochains événements, inscrivez-vous à notre Newsletter ou suivez-nous sur Linkedin.

